Table detection with SCIPY_PROJ method#
This is the default method for table detection.
The algorithm behind this method can be approximately described as follows:
We start from a grayscale pre-processed image from
dawsonia.image_preproc.Preprocessor.preprocess()which undergoes the following:colors transformed to grayscale
background noise removed
corrective rotation applied (optional)
text removed, grid lines filtered out and thickened
Distinct tables are identified using
scipy.ndimage.label()which assigns a label to a group of connected lines. Seedawsonia.table_detect.scipy_proj.table_detect_scipy_proj()for the implementation.The function
dawsonia.table_detect.scipy_proj.projections_of_label_tables()applies projection along horizontal and vertical directions.For different values of a factor called
sensibility, the functiondawsonia.table_detect.scipy_proj.get_table_structure()identifies peaks to get x and y coordinates for every row and column.Row heights and column widths are calculated using
dawsonia.table_detect.scipy_proj.get_position().Table cells are sorted in left-to-right, top-to-bottom order using
dawsonia.table_detect.scipy_proj.sort_insertion().Leading row and columns are removed (optional)
If the detected table structure matches the configuration specified in the divided_tables and section definitions of the .toml file, the result is saved to the output lists.
The functions
dawsonia.table_detect.utils.apply_row_manipulation()anddawsonia.table_detect.utils.apply_col_manipulation()are called to handle tables that are divided into multiple row or column sections.
%matplotlib inline
import matplotlib.pyplot as plt
We start by setting the environment variable in Bash,
export DAWSONIA_DEBUG_TABLE_DETECT=1
or in the Python console:
import os
os.environ["DAWSONIA_DEBUG_TABLE_DETECT"] = "1"
Now, you need some data to get started. The HTR model weights and data file strucuture are stored in another git repository.
!git clone https://git.smhi.se/ai-for-obs/data.git
Input data and table formats configuration#
The data repository contains a PDF (we support both PDFs and Zarr files of all formats) with scans from the weather station 144300.
%ls -1 data/raw/144300/
144300_1957-01-01_1957-12-31.pdf*
Before we start we need to at least create a table formats configuration file. We do that by manually viewing the files. Visually we know that there are:
3 tables in first page and 2 tables in the second page
each have a distinct number of rows and columns
3 tables that contains numeric values that are of interest to us (first page)
the column and row names which are static values
Some columns and rows only being separated by dots and not continuous lines. This requires some configuration for column sections and row sections.
row sections in all tables
column sections in the third table
The name of the file is important. Notice that the stem of the configuration file is the same as the parent directory which holds the books, which is 144300.
%mkdir -p table_formats
%%file table_formats/144300.toml
# NOTE: that the file name matches the directory containing the files.
[default]
version = 0
[default.preproc]
corr_rotate = false
idx_tables_size_verify = [0, 1, 2] # table_modif below needs to describe
# whether leading rows and columns should be removed from these tables
method = "SCIPY_PROJ"
row_idx_unit = "NONE"
table_modif = [[1, 1], [1, 1], [1, 1]] # This denotes how many
# leading rows and columns to remove from table 0,1 and 2.
# Each element is constructed [nrows to remove, ncols to remove]
[version.0]
# column sections describe whether any columns (including leading columns) are separated by non-continuous lines
# [cols,nsections]
col_sections = [
[[1,30]], # first table consists of 30 singular columns
[[1,30]], # second table consists of 30 singular columns
[[1,11], [2,8]] # third table consists of 11 singular columns
# and then 8 sections that each need to be divided into two columns each
]
#describing column names left after contingent removal of leading columns and division of column sections
columns = [
[
"h_1",
"h_2",
"h_3",
"h_4",
"h_5",
"h_6",
"h_7",
"h_8",
"h_9",
"h_10",
"h_11",
"h_12",
"h_13",
"h_14",
"h_15",
"h_16",
"h_17",
"h_18",
"h_19",
"h_20",
"h_21",
"h_22",
"h_23",
"h_24",
"Dagssum",
"Dagsmed",
"Dagsmax",
"Dagsmin",
"Diff"
],
[
"h_1",
"h_2",
"h_3",
"h_4",
"h_5",
"h_6",
"h_7",
"h_8",
"h_9",
"h_10",
"h_11",
"h_12",
"h_13",
"h_14",
"h_15",
"h_16",
"h_17",
"h_18",
"h_19",
"h_20",
"h_21",
"h_22",
"h_23",
"h_24",
"Dagssum",
"Dagsmed",
"Dagsmax",
"Dagsmin",
"Diff"
],
[
"h_1",
"h_4",
"h_7",
"h_10",
"h_13",
"h_16",
"h_19",
"h_22",
"Dagssumma_rel_fukt",
"Dagsmedel_rel_fukt",
"h_1_rikt",
"h_1_hast",
"h_4_rikt",
"h_4_hast",
"h_7_rikt",
"h_7_hast",
"h_10_rikt",
"h_10_hast",
"h_13_rikt",
"h_13_hast",
"h_16_rikt",
"h_16_hast",
"h_19_rikt",
"h_19_hast",
"h_22_rikt",
"h_22_hast"
]
]
# Table sizes after division according to col_sections and row_sections. Including leading columns and rows.
divided_tables = [
[34, 30],
[34, 30],
[34, 27]
]
name_idx = ["x_idx_0", "x_idx_1", "x_idx_2"]
# row sections describe whether any rows (including leading rows) are separated by non-continuous lines
# [rows,nsections]
row_sections = [
[
[1, 1], # The first table has one leading row, then
[5, 5], # five sections that should be divided into 5 rows each, then
[6, 1], # one section that should be divided into 5 rows, then
[1, 2], # two regular rows
],
[
[1, 1], # The second table has one leading row, then
[5, 5], # five sections that should be divided into 5 rows each
[6, 1], # one section that should be divided into 5 rows, then
[1, 2], # two regular rows
],
[
[1, 1], # The second table has one leading row, then
[5, 5], # five sections that should be divided into 5 rows each
[6, 1], # one section that should be divided into 5 rows, then
[1, 2], # two regular rows
]
]
#row names after contingent removal of leading rows and division of row sections
rows = [["1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20", "21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31", "Timsumma", "Timmedel"], ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20", "21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31", "Timsumma", "Timmedel"], ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20", "21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31", "Timsumma", "Timmedel"]]
# Table sizes before division according to row_sections and col_sections
# [nrows, ncols]
tables = [
[9, 30],
[9, 30],
[9, 19]
]
Writing table_formats/144300.toml
Demo: Table detection#
Now that we have all the prerequisites read, let’s execute the command:
DAWSONIA_DEBUG_TABLE_DETECT=1 dawsonia label --first-page 1 --last-page 1 --no-interactive data/raw/144300/144300_1957-01-01_1957-12-31.pdf
or its Python API equivalent:
from dawsonia import label
label.command("data/raw/144300/144300_1957-01-01_1957-12-31.pdf", 1, 1, interactive=False)
INFO 2026-03-09 10:27:16,061 - dawsonia.io._pdf - INFO - table_format = TableFormat(name_idx=['x_idx_0', 'x_idx_1', 'x_idx_2'], columns=[['h_1', 'h_2', 'h_3', 'h_4', 'h_5', 'h_6', 'h_7', 'h_8', 'h_9', 'h_10', 'h_11', 'h_12', 'h_13', 'h_14', 'h_15', 'h_16', 'h_17', 'h_18', 'h_19', 'h_20', 'h_21', 'h_22', 'h_23', 'h_24', 'Dagssum', 'Dagsmed', 'Dagsmax', 'Dagsmin', 'Diff'], ['h_1', 'h_2', 'h_3', 'h_4', 'h_5', 'h_6', 'h_7', 'h_8', 'h_9', 'h_10', 'h_11', 'h_12', 'h_13', 'h_14', 'h_15', 'h_16', 'h_17', 'h_18', 'h_19', 'h_20', 'h_21', 'h_22', 'h_23', 'h_24', 'Dagssum', 'Dagsmed', 'Dagsmax', 'Dagsmin', 'Diff'], ['h_1', 'h_4', 'h_7', 'h_10', 'h_13', 'h_16', 'h_19', 'h_22', 'Dagssumma_rel_fukt', 'Dagsmedel_rel_fukt', 'h_1_rikt', 'h_1_hast', 'h_4_rikt', 'h_4_hast', 'h_7_rikt', 'h_7_hast', 'h_10_rikt', 'h_10_hast', 'h_13_rikt', 'h_13_hast', 'h_16_rikt', 'h_16_hast', 'h_19_rikt', 'h_19_hast', 'h_22_rikt', 'h_22_hast']], rows=[('1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', 'Timsumma', 'Timmedel'), ('1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', 'Timsumma', 'Timmedel'), ('1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', 'Timsumma', 'Timmedel')], tables=[[9, 30], [9, 30], [9, 19]], row_sections=[[[1, 1], [5, 5], [6, 1], [1, 2]], [[1, 1], [5, 5], [6, 1], [1, 2]], [[1, 1], [5, 5], [6, 1], [1, 2]]], col_sections=[[[1, 30]], [[1, 30]], [[1, 11], [2, 8]]], divided_tables=[[34, 30], [34, 30], [34, 27]], preproc=PreprocConfig(table_modif=[[1, 1], [1, 1], [1, 1]], corr_rotate=False, row_idx_unit=<TimeUnits.NONE: 3>, method=<PreprocMethods.SCIPY_PROJ: 1>, idx_tables_size_verify=[0, 1, 2]), transforms=None, version='0', station='144300')
INFO 2026-03-09 10:27:16,079 - dawsonia.io._pdf - INFO - PDF metadata: {'pages': 24, 'metadata': {'CreationDate': "D:20250609083704+01'00'", 'ModDate': "D:20250613080108+02'00'", 'Producer': 'GS PDF LIB v0.002', 'Title': ''}}
INFO 2026-03-09 10:27:16,081 - dawsonia.io._pdf - INFO - Setting first_page = 1
INFO 2026-03-09 10:27:16,082 - dawsonia.io._pdf - INFO - Opening PDF data/raw/144300/144300_1957-01-01_1957-12-31.pdf to extract pages 1–2
INFO 2026-03-09 10:27:16,091 - dawsonia.io._pdf - INFO - Total 24 pages detected; reading up to 2
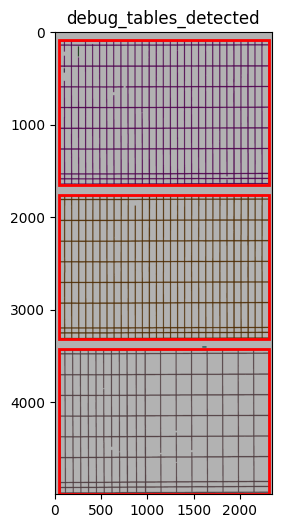
INFO 2026-03-09 10:27:23,623 - dawsonia.table_detect.scipy_proj - INFO - Detected nb_labels_pass = 3
INFO 2026-03-09 10:27:23,625 - dawsonia.table_detect.scipy_proj - INFO - with sensibility = 0.9: l_size = [[9, 28], [9, 30], [9, 19]]
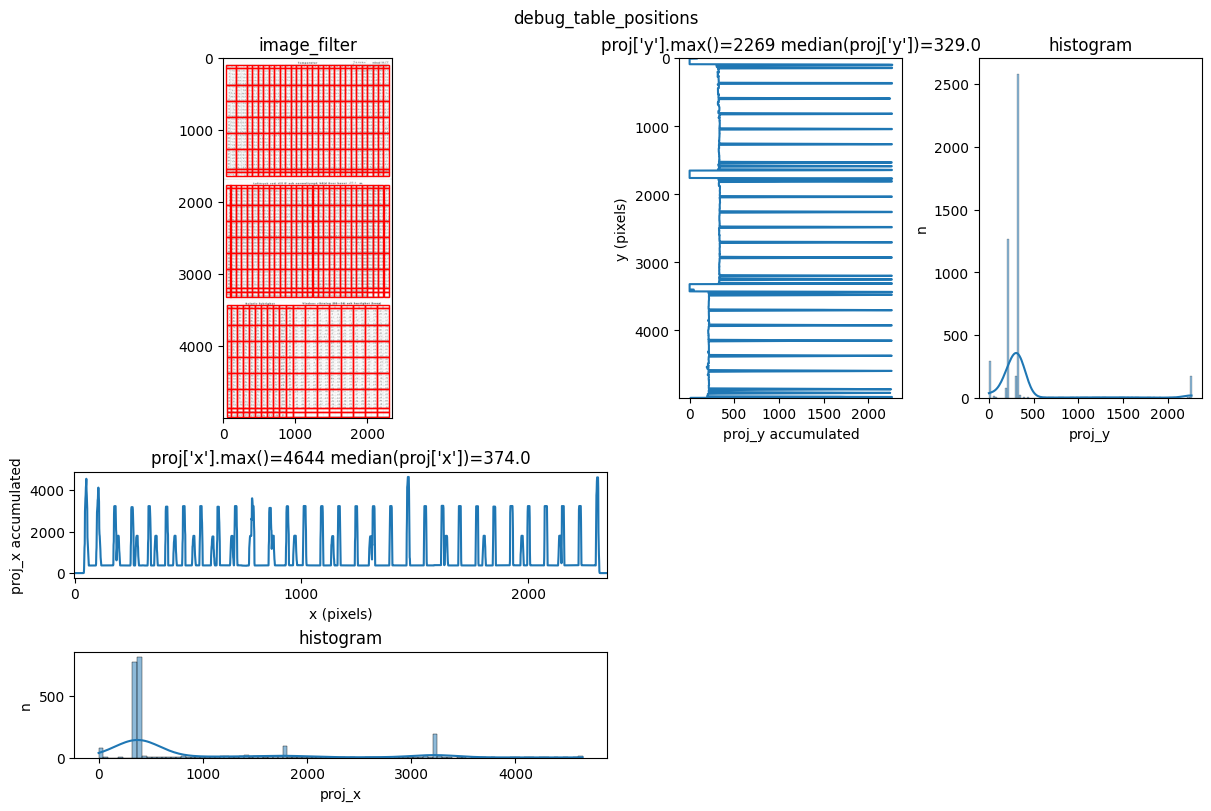
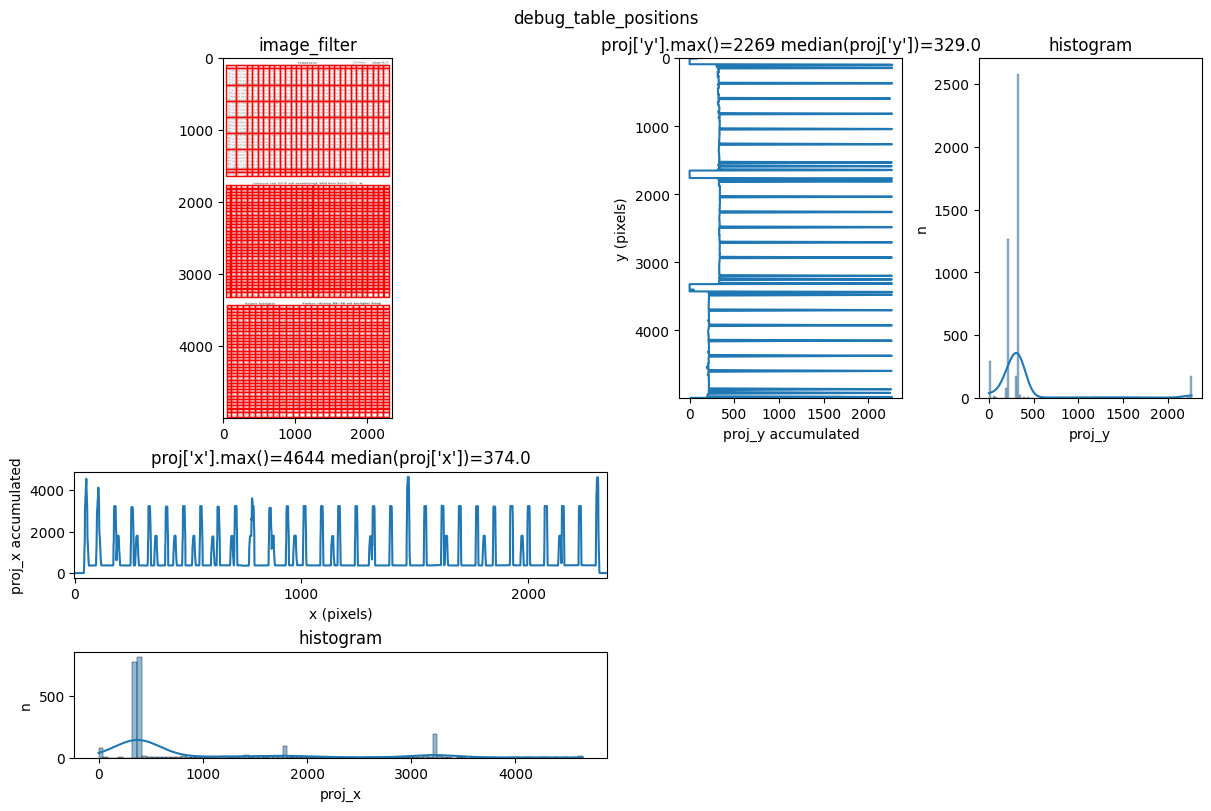
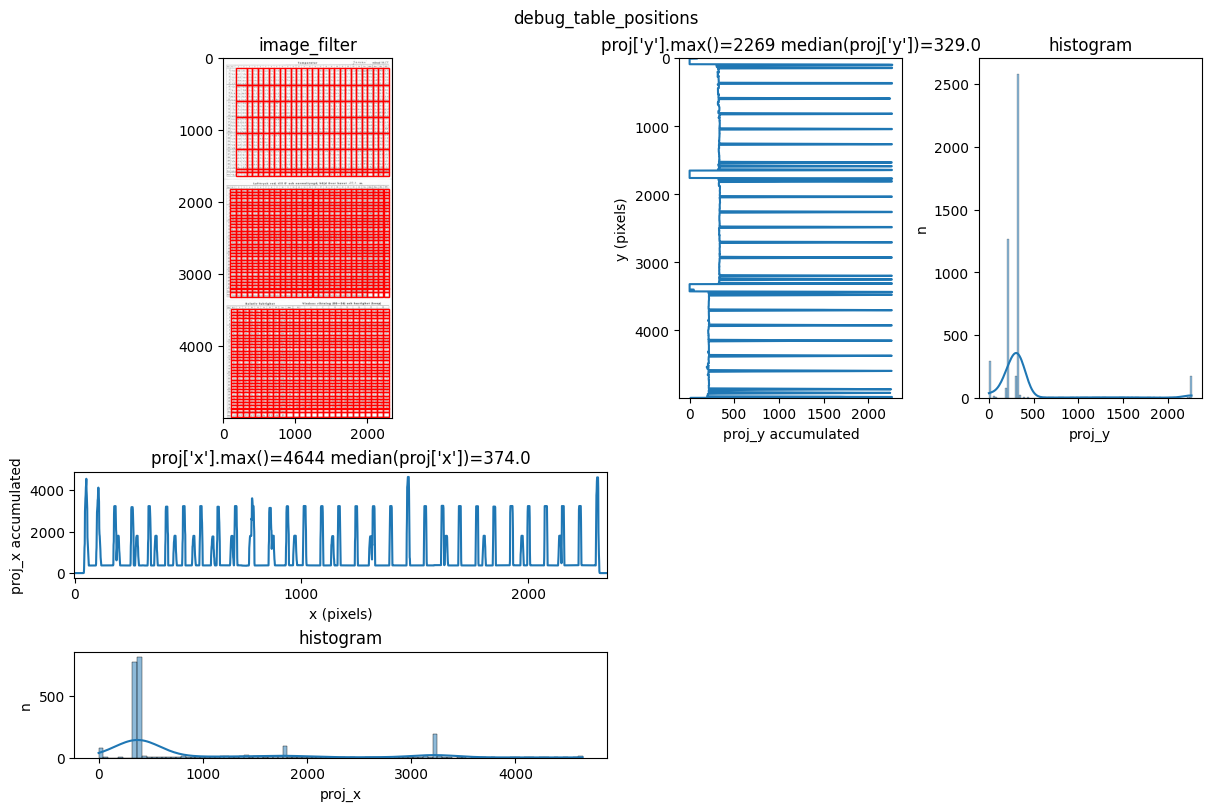
INFO 2026-03-09 10:27:28,621 - dawsonia.table_detect.scipy_proj - INFO - saving table 1
INFO 2026-03-09 10:27:28,622 - dawsonia.table_detect.scipy_proj - INFO - saving table 2
INFO 2026-03-09 10:27:28,624 - dawsonia.table_detect.scipy_proj - INFO - with sensibility = 0.7: l_size = [[9, 30], [9, 30], [9, 19]]
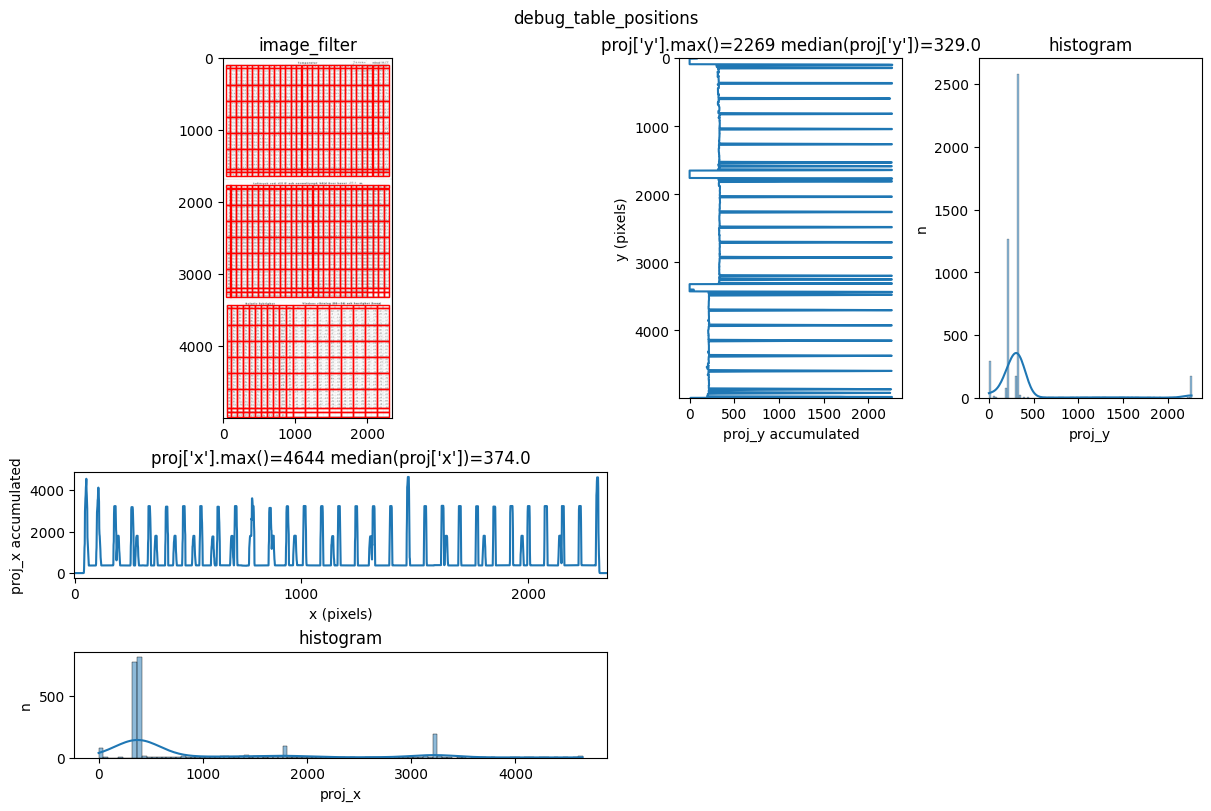
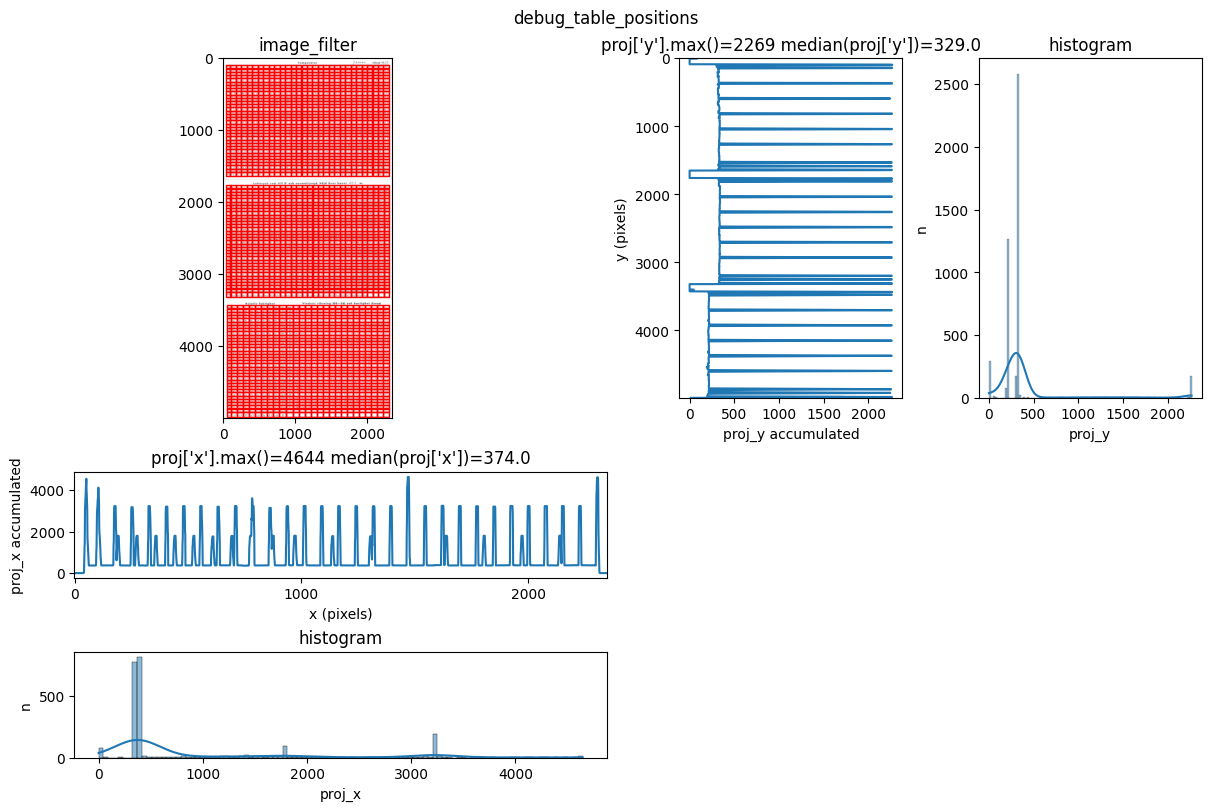
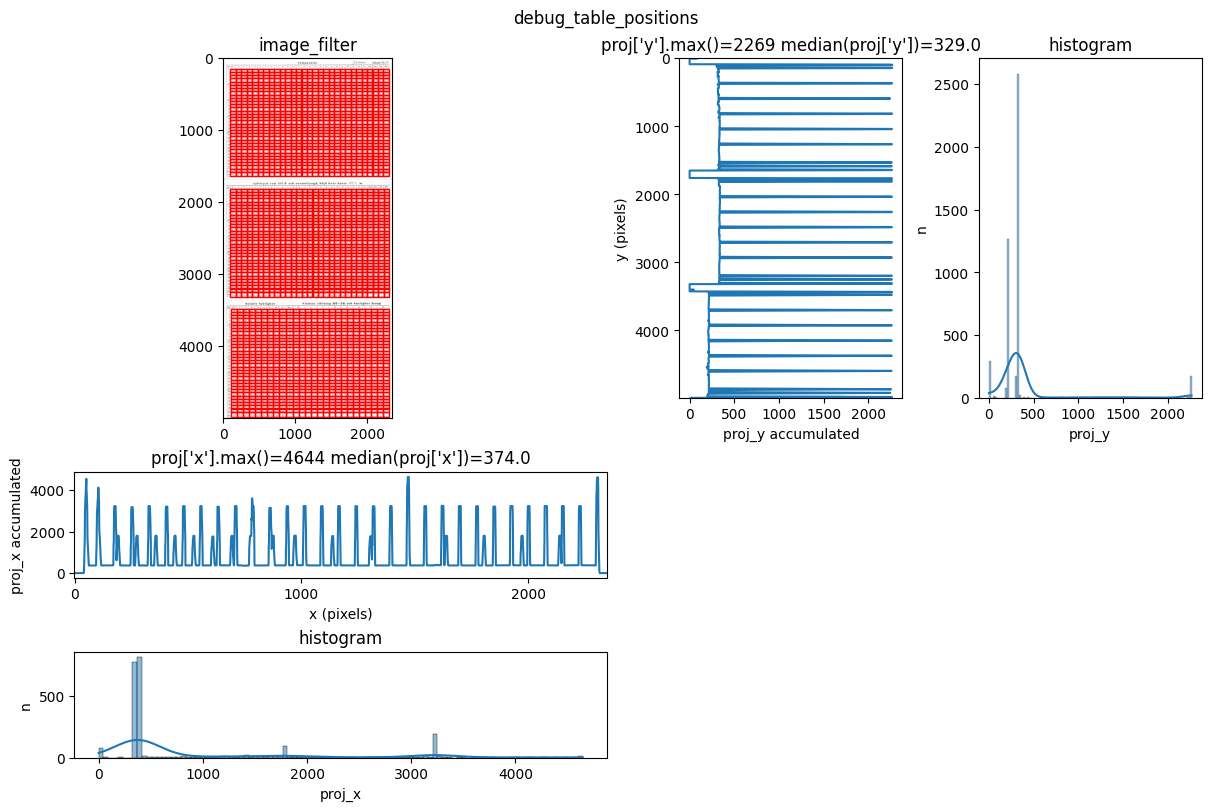
INFO 2026-03-09 10:27:34,248 - dawsonia.table_detect.scipy_proj - INFO - saving table 0
INFO 2026-03-09 10:27:34,250 - dawsonia.table_detect.utils - INFO - 🌞 final size of tables: [[33, 29], [33, 29], [33, 26]]
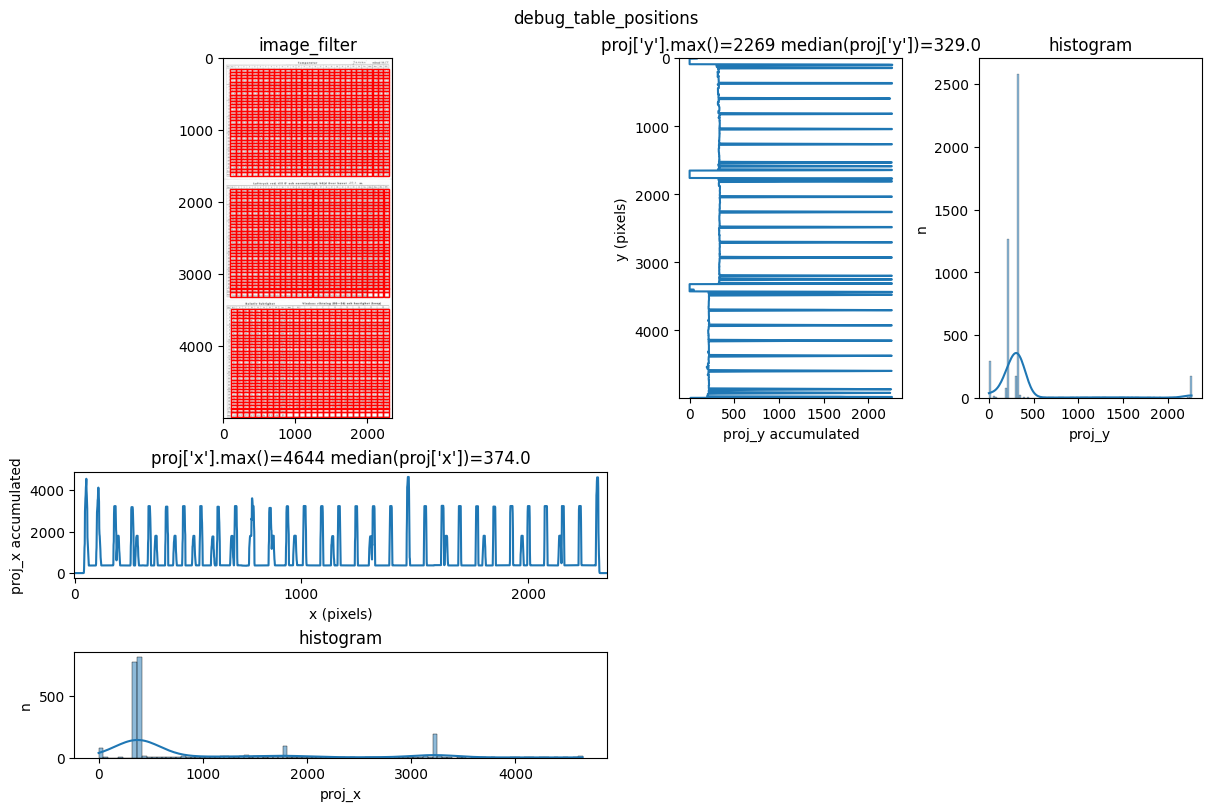
We can see that dawsonia was successful in finding all tables on the first page since it says: Final size of tables [[33, 29], [33, 29], [33, 26]]. That is the full table sizes without the leading rows and columns.